Apache Kafka is a distributed, scalable, fault-tolerant messaging system. It is a publish-subscribe based system that enables the parallel processing of messages. Its durability, reliability, and replicability properties mean Kafka can be broadly visualized as a platform that facilitates data storage and real-time stream processing of data. Apache Kafka-based applications can be built using Amazon MSK. Amazon MSK offers console-based setup and configuration along with continuous monitoring of the cluster to prevent server downtime in the application. This article provides an overview of how to create a Spring Boot application using Amazon MSK.
Spring for Apache Kafka
Spring is provided with the Spring template model, i.e., Spring for Apache Kafka. The Kafka support to the application can be included by adding the following Maven Dependency in the pom.xml file.

Amazon MSK Setup
At the outset, we are required to create a cluster in the Amazon MSK console. During setup, the connection with AWS MSK, the zookeeper and the broker servers is essential. The details of the broker servers are required while configuring the producer and consumer properties for sending and receiving messages, while zookeeper details are required to create the topic.

Topic Creation:
The next step is to create a topic in Kafka. Let us create a topic “demoTopic” by executing the following command in AWS SSH.

Publishing Messages:
With this, let us configure the producer properties followed by the Kafka Template for sending messages to the Kafka Topic. To do this, we need to create a configuration class and add the following producer instances:
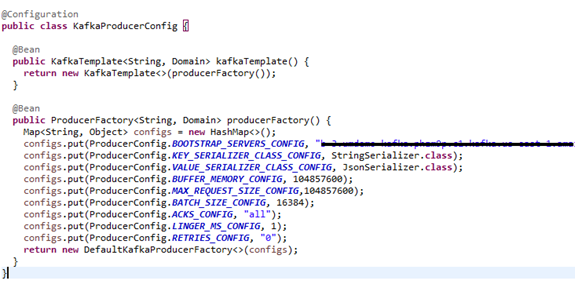
To send a message to the Kafka Topic, the KafkaTemplate is used. This requires the following snippet:

Consuming Messages:
To consume the messages, we require the following consumer configurations. These will enable the detection of the consumers based on the @KafkaListener annotation. The group id (below) specifies the consumer group to which the consumer belongs.
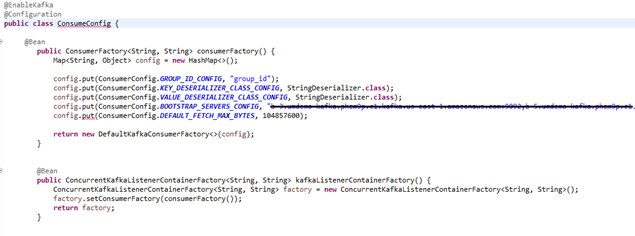
Message consumption can be from multiple topics, and multiple consumers can consume a message from the same topic as follows:

Performance Optimization:
To further tune and optimize the performance of Kafka, there are certain factors in the producer, consumer and broker side that need to be considered. These are configured to strike a perfect balance between the high throughput and low latency features of Kafka. Improvement in the producer property would achieve increased durability, reliability, throughput, and lower latency, which can be achieved as follows:
To ensure that there is no loss of messages, producer acknowledgement is set to all. A batching and buffering approach is used to keep a check on throughput and latency. Batch size — which is set in bytes — is configured along with the linger time that specifies the maximum time the batch is provided to fill. The message is sent to whichever topic occurs earlier. Along with this, the buffer memory, equal to the batch size, is configured to store the unsent messages.
AWS Deployment:
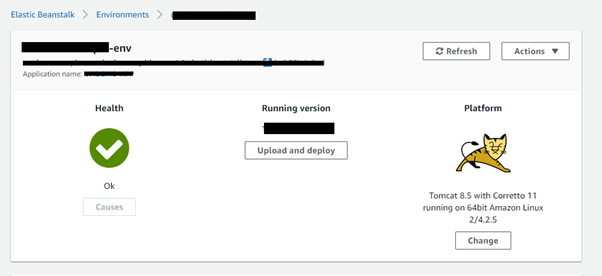
With this, the configurations for publishing and consuming messages with Kafka is completed. To observe the working of the application, Kafka must be deployed in Elastic Beanstalk. For the deployment, the .war file of the application is required. To deploy in AWS, open the Elastic Beanstalk from the services and create an environment for its deployment. Finally, upload the .war file from the “Upload and Deploy” and your application with Amazon Managed Kafka will be up and running.
Through this article, we attempted to provide an overview on how to configure Amazon MSK for creating a Spring Boot application that makes use of Apache Kafka as its messaging middleware.